The MHP software stack is a complex piece of design. A complete version of MHP-compliant middleware will be many tens of thousands of lines of code in all probability, and this means that getting the architecture right is a major factor in the ease of implementation.
One of the great things about the MHP APIs is that many of them can be built on top of other MHP APIs. This layered approach makes it possible to take a very modular approach to building the software stack. The diagram below shows how these APIs can be built on top of each other. Each API in the diagram is built on top of the ones below it, and is used internally within the software stack as well as by MHP applications.
While not every MHP stack will be built this way, it gives you an idea of how the APIs fit together conceptually, if not actually in practice. Exactly how closely a particular implementation will follow this depends on a number of factors. Implementations where more of the code is written in Java will probably follow this more closely than those implementations that are mostly written in C or C++, for instance. Similarly, the operating system and the hardware capabilities of you platform will play a part. Platforms where most of the work is done n software have a little more freedom in their design, and so they may be more likely to follow this approach.
Clicking on the diagram below will take you to a desription of how the APIs fit together.
An overview of the MHP software stack.
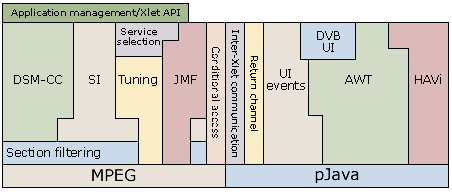
One important API is missing from this diagram. The shaded APIs are built on top of the DAVIC resource notification API. This allows all of the APIs that directly use scarce resources to handle these resources in the same way.
The APIs can be split more or less into two parts. One of these parts deals with services relating to MPEG and MPEG streams. The other part provides services built directly on top of the pJava APIs. The main differences between these two parts is that the MPEG-related APIs will be tied much more closely with the underlying hardware platform, since the platform will typically provide services for secion filtering and possibly SI table parsing. In particualr, the link between the media control components and the underlying hardware will be very close, and the JMF component may only be a very thin layer on top of the hardware MPEG decoders in the CPU.
At the core of the MPEG-handling APIs lies the MPEG section filtering APIs. Almost all of the other MPEG-related APIs build on this in some way. The service information APIs need to parse those sections that contain the SI tables in order to build the SI database that forms the core of the SI component. While it could use a proprietary API or accessing the section filters that are needed, using the section filtering API may be equally easy.
The DSM-CC API needs to parse the DSM-CC sections directly, while using the service information API to find out which streams in a service contain DSM-CC object carousels. In this case, there is a benefit to using the SI API if possible, although the filtering of DSM-CC sections may be handled at a lower level for performance reasons. It’s possible to use the section filtering API to handle this, but unless you have a very fast platform, the performance cost may be too high.
All of these APIs depend on the underlying section filtering support. When using hardware section filters, it may be easiest for the SI APIs and DSM-CC component to use these section filters directly rather than going via the Java section filtering API. Since all of these APIs require fast responses when filtering sections, building them directly on the native section filtering API might make more sense. In the case of a software section filteirng solution, then going through the MHP section filtering API may not offer as much of a performance penalty as it would do otherwise.
The tuner control API relies on the SI API in order to locate the transport stream that it should tune to. Once it has the correct frequency and polarity information (which it may get from scanning the network or from user settings, neither of which have an MHP API) it will access the tuner hardware directly in order to tune to the correct transport stream.
JMF uses the service information APIs to translate a DVB locator into a set of PIDs for the MPEG streams that the locator refers to. It also uses the service information API to provide the functionality for some of the common JMF controls, such as the language control. Once JMF has located the appropriate streams, it will typically access the MPEG decoder hardware directly to decode the stream. In this case, the MPEG decoding hardware or the implementation of the software MPEG decoder will often decode the appropriate PIDs directly from the transport stream.
Now that we’ve seen the low-and mid-level APIs for MPEG access, we can see the two higher level APIs that use them. The JavaTV service selection API uses the service information API in order to find the service that it should tune to. Once it has done this, it uses the tuning API and JMF to tune t the correct transport stream and display the right service.
The application management API builds on top of the service selection API, service information and DSM-CC. Although we have implied in this diagram that the application management component uses the service selection API, the picture is more complex in reality. While the application management relies on the service selection API (in that every application is associated with a service, and thus a service context (see the tutorial on the service selection API for details of this), the relationship between the service selection API and the application manager is deeper than this. The service selection API uses the application management API to kill the applications that need killing, when a new service is selected or when a service context is destroyed.
The Conditional access API will usually talk to the CA hardware directly. This is partly due to efficiency issues, as with JMF, but paranoia plays a much larger part. CA vendors are extremely careful about what communicates with the CA subsystem, and so this interface is likely ot be as simple as possible. Since most of the work is carried out in the CA subsystem itself, rather than in the middleware, there is little to be gained from using any of the other APIs in any case.
That accounts for all of the MPEG-based APIs, with a few exceptions. Support for JavaTV and MHP locators is not normally based on top of the service information API, partly because the service information that’s currently available may not be enough to decide if a locator is valid. While this API is conceptually located between the service information API and the APIs that use it, this is not guaranteed to be the case.
Turning our attention to the other APIs, the most obvious place to start is AWT. Due to the differences in the application model and the graphics hierarchy between MHP and normal Java implementations, there are a few changes needed here from the AWT that we know and love. The biggest of these is that many of the AWT widgets have been removed. Since the platform does not necessariyl have a window manager, most of the heavyweight widgets are not required by MHP.
The HAVi Level 2 GUI API builds on top of AWT, since many of the classes in the HAVi widget set are subclasses of the equivalent AWT widgets (although they will probably not be implemented using the AWT widgets, because these are not required by MHP). At the same time, there are many elements of the HAVi API which are completely new and which are based directly on pJava – HScenes, for instance. To further complicate matters, the HAVi API also inter-works with JMF, in order to make sure that some of the video/graphics integration features work correctly. It may not build directly on top of JMF, however.
The DVB UI API also builds on top of AWT. In most cases, this is merely extending AWT’s functionality in ways that may already be included (depending on the version of AWT which is used). Some elements, especially alpha blending, may use the underlying hardware directly instead. Alpha blending is a very demanding task that simple can’t be carried out in Java, and so this is normally carried out in hardware by the graphics processor.
Due to the changes in the way user input events are handled, AWT also uses the UI events API. This is used directly by applications as well, of course, but the UI event API will redirect user input events into the normal AWT event handling process.
The other APIs are mostly independent. The return channel API uses the DAVIC resource notification API, since most STBs will use a normal PSTN for the return channel if they have one. In this case, the return channel is a scarce resource, which may not be the case with a cable modem or ADSL return channel.
The inter-xlet communication API needs to work very closely with the application management API in order to do its job properly. Stub classes created by the inter-xlet communication API must be loaded by the correct classloader (see the tutorial on inter-Xlet communication to understand why). In order to do this, the inter-xlet communication API must know which classloader corresponds to which application, and this requires careful coordination with the application management API. This is typically built on a private API , however, since none of the MHP APIs really do what is necessary.
Implementation issues
As with any piece of complex software, there are a few issues that people implementing an MHP software stack need to be aware of. This isn’t intended to be a complete list, but it will give you an idea of the areas that need some care.
The main factor when developing an MHP stack is paranoia – you as a middleware author have no control over what the applications do; and with middleware as powerful and flexible as MHP this is a recipe for potential problems. Middleware implementers have to design their software stack in such a way that an application can’t cause other applications or the middleware itself to become unstable.
Probably the most complex part of the architect’s job is making sure that threads are used effectively. This is harder than in some cases because of Java’s event handling model – event handling threads started by the middleware move into the user space in order to execute the event handler, before (hopefully) returning to the middleware space in order to handle the next event. The problem here is making sure that a downloaded application doesn’t spend too much time in the event handler, tying up a thread that should be used to handle other events. Unfortunately, since the middleware developer doesn’t have any control over downloaded applications, this can’t be guaranteed.
While there are several solutions to this, all of them involve creating a pool of threads for event handling. Each application may have its own thread (or threads) for event handling, or applications may share a set of threads. The important thing here is to make sure that no critical middleware threads are used to send events to an application. Allocating threads from a separate event handling pool means that no matter what an application does, only downloaded applications will be affected. Indeed, if each application has a separate thread, then other applications will also remain unaffected.
There is a related issue that needs to be considered: applications that spend too long in an event handling thread may allow a queue of other, undelivered, events to build up. This can cause its own problems for the middleware, since all these events have to be stored somewhere. While a receiver will probably have enough memory to handle them, some real-time operating systems impose other constraints on memory use. An implementation needs to take care that events which are waiting to be dispatched don’t take up too much memory. This can be done by restricting the amount of events that may be queued, and again this can be done for each application separately, or as a global setting for all applications.